
Last week my father was cleaning out some old boxes and came across a few dozen old floppy disks. These were all in sky blue sleeves with rainbow labels that said “Konica PC PictureShow”. The disks were still in great condition, so I thought it would be fun to see what was on these photo time capsules from yesteryear.
The Problem
Just before the turn of the century, Konica partnered with photo shops and drugstores to run a scanning service for home photos. After developing your pictures, they would scan your film for a small fee ($3.99 for up to 27 exp., $5.99 for up to 36 exp.) and give you a floppy disk with digital photos and a copy of the Konica “PC PictureShow” program. The program automatically loads the images on the disk and lets you view photos on your PC. The scans are only 600 x 400 pixels, but that was plenty large for your average home snapshots back in 1999.
Modern computers and operating systems still support floppy drives and the FAT filesystem, so in theory I should be able to plug in the drive, pop in a disk, and then see the photos. Right?
“This app can’t run on your PC”
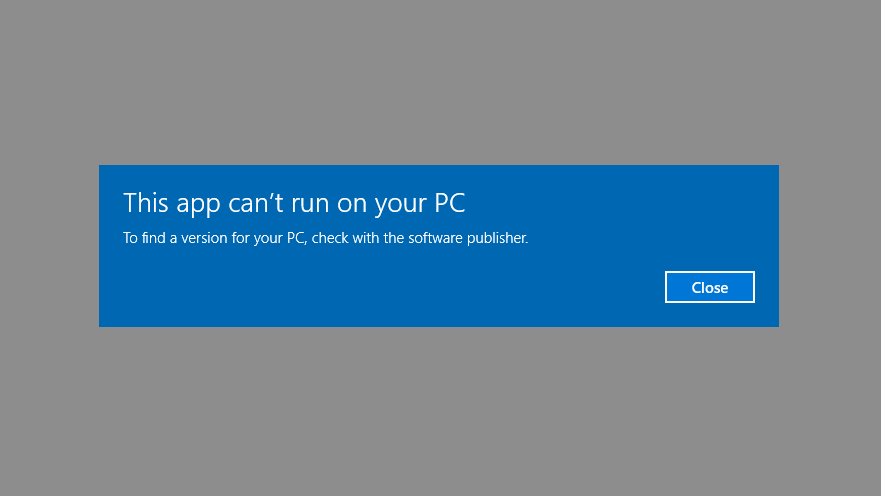
Wrong.
The first problem is the age of the software. Konica merged with Minolta to form Konica Minolta in 2003, and Konica Minolta then got out of the camera business in 2006 – selling most of its operations to Sony. The disks I have are dated from 1999 through 2001, putting the software in the age of Windows 98 to Windows Me – and because of the company mergers and dissolution of their scanning service it hasn’t been updated since.
Although each floppy drive has a copy of the “PC PictureShow” software executable, attempting to run the software on Windows 10 (v.1909) results in a “This app can’t run on your PC” error. The software on the floppies varies in version numbers between 3.0.6 (1997) and 3.70 (2001), but no version of the software that I could find will run on modern versions of Windows, with or without “compatibility mode” enabled.
But this shouldn’t be a problem – the old software is just one way to view the image files, right?
“How do you want to open this file?”
I wish. As it turns out, all of these images are stored as “Konica Quality Photo” (.KQP) files – a proprietary digital file format developed by Konica for PC PictureShow and their other products. If you want to view the photos, you have to use Konica’s software.
There are a number of modern third party programs out there that can reportedly open and convert .KQP files such as XnView, although I had no luck with any of them. They all threw errors and said they didn’t recognize the file format for the images. I also found a handful of paid programs that claimed they could open and convert .KQP files, but I didn’t want to spend the money if I could solve the problem myself.
Time for plan B.
Step 1: Copying to PC
Before anything else I needed to copy all of the images off of the floppy disks and onto my computer’s hard drive.
Although floppy drives are neat retro tech, they’re almost unimaginably slow from a modern perspective – measuring in bits per second (10), compared to megabytes (106 * 8) per second with an SSD. Much better to copy all of the photos to the PC and then deal with them as a batch.
There are two wrinkles to this process. First, all of the disks use a standard naming convention: the early disks (1999-07/2000) use a two-digit scan number, while the later disks (08/2000-2001) use both a two-digit scan number and the frame number of the roll, separated by an underscore.
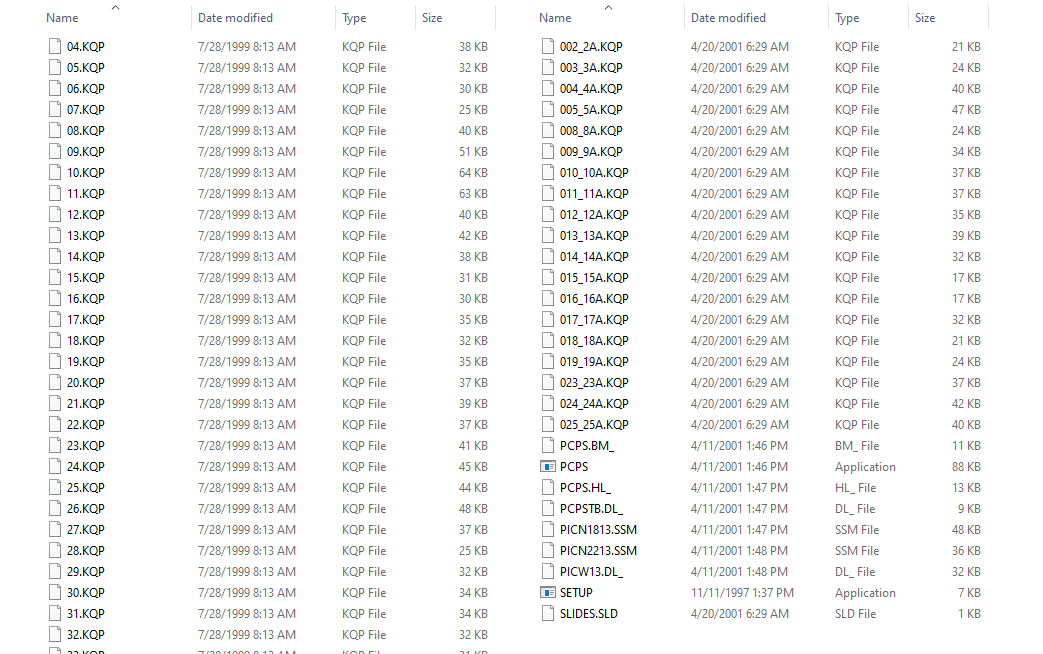
Konica PC PictureShow original filenames – 1999 (left) and 2001 (right)
This is a problem, since this will result in name collisions if the files are copied into the same folder. You can get around this by putting the files into subfolders, but that creates a different issue as the “PC PictureShow” program will only show files in the parent folder. So these images will need to be renamed as they’re copied.
The second issue is that of missing metadata. The photos all have file timestamps from when they were scanned, and some of the floppy disks themselves have written annotations on the label about when or where the photos were taken. It would be nice to preserve these annotations in the copied files.
Instead of doing this by hand I decided to automate the process with a Python (3.8) script. The script takes two command-line arguments: the source directory to read from (typically the floppy drive, A:\) and the destination directory to copy to. After inserting a disk, the script will create a list of .KQP files and generate a unique prefix composed of the date the disk was made (using the ‘modified’ time from the first image) and a unique identifier character per disk (‘A’ through ‘Z’). This identifier will increment if there are existing images with that date in the destination folder, so each disk per date will have its own character. The user can also enter a description that will be postpended to the end of the prefix for each image.
After hitting ‘enter’, the script will automatically copy all of the present .KQP files on the disk into the destination folder and then rename them with the auto-generated prefix. It then returns to the start, so multiple disks can be digested without having to reinput the source and destination options.
This worked pretty well, and I was able to copy all 21 disks within a half hour. One of the disks was a bit degraded and caused the script to freeze while copying files, so those files were copied by hand to a temporary folder and then digested from there. In total, I was able to successfully copy 479 out of the 483 images off of the disks.
In case it’s useful to anyone, here is the Python script in full – licensed under MIT:
# Project Konica PC PictureShow (.KQP) Floppy Copier Script
# @author David Madison
# @link partsnotincluded.com
# @license MIT - Copyright (c) 2020 David Madison
# Permission is hereby granted, free of charge, to any person obtaining a copy
# of this software and associated documentation files (the "Software"), to deal
# in the Software without restriction, including without limitation the rights
# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
# copies of the Software, and to permit persons to whom the Software is
# furnished to do so, subject to the following conditions:
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
# THE SOFTWARE.
import os
import shutil
from datetime import datetime
import time
import argparse
class ProgressBar:
"""
Generates a progress bar for the console output
Args:
pre (str): string to prepend before the progress bar
bar_length (int): length of the progress bar itself, in characters
print_elapsed (bool): option to print time elapsed or not
Attributes:
pre (str): string to prepend before the progress bar
bar_length (int): length of the progress bar itself, in characters
print_time (bool): option to print time elapsed or not
print_elapsed (int): starting time for the progress bar, in unix seconds
"""
def __init__(self, pre="", bar_length=25, print_elapsed=True):
pre = (pre + '\t') if pre != "" else pre # append separator if string present
self.pre = pre
self.bar_length = bar_length
self.print_elapsed = print_elapsed
if self.print_elapsed:
self.__start_time = time.time() # store start time as unix
def write(self, percent):
"""Prints a progress bar to the console based on the input percentage (float)."""
#term_char = '\r' if percent < 1.0 else '\n' # rewrite the line unless finished
term_char = '\r'
filled_size = int(round(self.bar_length * percent)) # number of 'filled' characters in the bar
progress_bar = "#" * filled_size + " " * (self.bar_length - filled_size) # progress bar characters, as a string
time_string = ""
if self.print_elapsed:
time_elapsed = time.time() - self.__start_time
time_string = "\tTime Elapsed: {}".format(time.strftime("%H:%M:%S", time.gmtime(time_elapsed)))
print("{}[{}]\t{:.2%}{}".format(self.pre, progress_bar, percent, time_string), end=term_char, flush=True)
class KonicaCopy:
def __init__(self, source, destination, extension=".KQP"):
self.dir_source = source
self.dir_destination = destination
self.extension = extension.lower()
if not os.path.exists(self.dir_destination):
os.makedirs(self.dir_destination)
self.filelist = []
self.prefix = ""
def create_uid(self, prefix):
"""
Finds a unique identifier character for the provided date prefix, in order to
avoid filename conflicts in the destination folder
Parameters:
prefix (str): string to search for at the start of each file, before UID
Returns:
next available UID character in the sequence (char)
"""
new_uid = 'A' # using letters, starting at 'A'
# build list of files in destination directory starting with prefix
filelist = []
files = [f for f in os.listdir(self.dir_destination) if os.path.isfile(os.path.join(self.dir_destination, f))]
for file in files:
if file.lower().endswith(self.extension) and file.startswith(prefix):
filelist.append(file)
# if conflicts are detected, find the next available uniqueness identifier
if filelist:
uids = []
prefix_length = len(prefix)
for file in filelist:
if len(file) > prefix_length + 2:
separator = file[prefix_length] # first character after prefix
id = file[prefix_length + 1] # second character after prefix
if separator == '_' and not id.isdigit():
uids.append(id)
if uids:
uids.sort()
new_uid = chr(ord(uids[-1]) + 1) # next letter
if ord(new_uid) > ord('Z'):
raise RuntimeError("Not enough uniqueness values to continue (A-Z taken for prefix {:s})".format(prefix))
return new_uid
def create_filelist(self):
"""
Creates a list of files in the "source" folder which have a matching
extension prefix
Returns:
list of filenames (list)
"""
self.filelist = []
files = os.listdir(self.dir_source)
for file in files:
if file.lower().endswith(self.extension):
self.filelist.append(file)
if not self.filelist:
print("ERROR: No {:s} files found out of {:d} items available".format(self.extension, len(files)))
return self.filelist
def create_prefix(self, description=""):
"""
From the stored filelist, creates a prefix to append to all copied files
including the original creation date, a unique identifier character for
the set, and an option description
Parameters:
description (str): the description to append to the end of the prefix
Returns:
prefix (str)
"""
if not self.filelist:
print("ERROR: No filelist for reference")
return # no filelist to build the prefix string
path_source = os.path.join(self.dir_source, self.filelist[0])
timestamp = os.path.getmtime(path_source) # last modified time
dt = datetime.fromtimestamp(timestamp)
date_prefix = "{:%Y-%m-%d}".format(dt)
uid = self.create_uid(date_prefix) # search for the date prefix
self.prefix = "{:s}_{:s}".format(date_prefix, uid)
if description:
self.prefix = "{:s}-{:s}".format(self.prefix, description)
return self.prefix
def copy(self, show_progress=False):
"""
Iterate through the stored "source" filelist and copy each file to the destination
directory, using the prefix generated in create_prefix()
Parameters:
show_progress (bool): if enabled, will print a progress bar to the console
Returns:
number of files copied successfully
"""
num_copied = 0
num_total = len(self.filelist)
progress = ProgressBar("Copying:")
for file in self.filelist:
if show_progress == True:
progress.write(num_copied / num_total)
path_source = os.path.join(self.dir_source, file)
new_file = "{:s}_{:s}".format(self.prefix, file)
path_dest = os.path.join(self.dir_destination, new_file)
try:
shutil.copy2(path_source, path_dest)
except IOError as e:
print("ERROR: A problem occured attempting to copy {:s} to {:s}".format(file, new_file))
else:
num_copied += 1
print("Successfully copied {:d}/{:d} photos to \"{:s}\" using prefix \"{:s}\"".format(num_copied, num_total, self.dir_destination, self.prefix))
return num_copied
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="KQP floppy drive copy script")
parser.add_argument("source", help="directory path for the floppy drive", type=str)
parser.add_argument("destination", help="directory path where images should be saved", type=str)
args = parser.parse_args()
floppy = KonicaCopy(args.source, args.destination)
print("\nKonica PC PictureShow (.KQP) Floppy Copier - v1.0")
print("By David Madison, partsnotincluded.com")
print("-----------------------")
print("Source: {:s}".format(floppy.dir_source))
print("Destination: {:s}".format(floppy.dir_destination))
print()
while(True):
prompt = input("Insert a disk and press 'Enter' to start, or type 'exit' to quit\t")
quit_args = { "quit", "q", "exit", "stop" }
if prompt in quit_args:
quit()
filelist = floppy.create_filelist()
num_total = len(filelist)
if(num_total == 0):
continue # return to beginning of loop
description = input("Found {:d} photos. What description do you want to use? (you can leave this blank)\t".format(num_total))
floppy.create_prefix(description)
input("Ready to copy {:d} photos, using prefix {:s}. Press \"Enter\" to continue.".format(num_total, floppy.prefix))
floppy.copy(show_progress=True) # hey you, copy that floppy!
print() # newline, for separation
This script was written to complete a specific task and is not polished. User beware…
Step 2: Rename (Again)
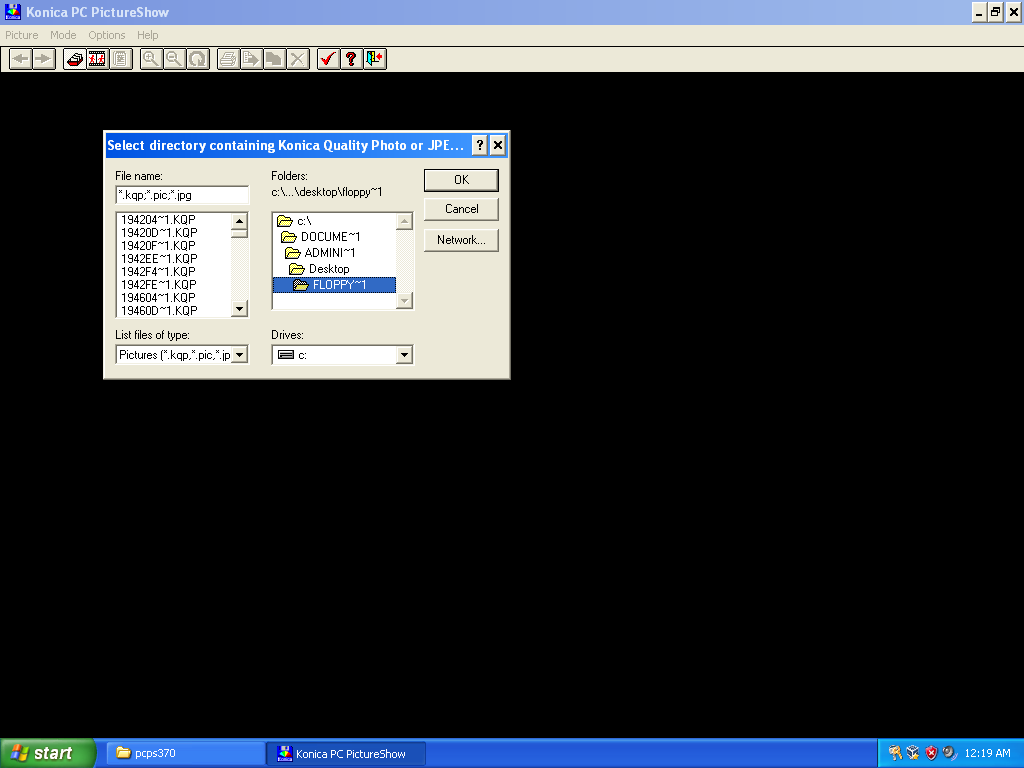
8.3 filenames as seen in the “Select Directory” prompt for the PC Picture Show software
Okay, now all of the images are renamed, copied, and safe and sound on my computer’s desktop! Time to rename them again.
Wait, what?
Remember when I said the “PC PictureShow” software was old? It turns out that it’s so old that it only supports 8.3 filenames – those short, squiggly (“~1”), all-capitalized filenames you saw while working with legacy software in old versions of Windows. The result is that all of those long, detailed filenames I took the effort to create in step 1 get truncated down to gibberish like 1952F8~1.KQP and 206535~1.KQP. Not only does this clear out the dates and descriptions I saved, but it also mixes up the file order so the exported files won’t be chronological.
Okay, time for plan B C. I didn’t want to lose all of that great metadata, so instead I’m going to save the original names to a text file, then rename the images to sequential filenames to make them as short as possible. Once the images are converted to JPEGs, I can then use that text file to rename the files back to their original filenames.
Because I didn’t want to do that tedious renaming by hand, I created yet another Python script (3.8) to do it for me. The script lists all of the files in a parent directory, saves both the original filenames and the sequential filenames into a specified CSV file, and then renames all of the images to their sequential names. Passing the --reverse (-r) option to the script reverses the process: reading from the specified CSV file, checking if any files in the folder match the sequential names, and renaming them back to their originals filenames if the strings match.
This is a little rough around the edges, but it does the job. As with the “copying” script above, here is the Python script in full — again licensed under MIT:
# Project Rename Reverse Script
# @author David Madison
# @link partsnotincluded.com
# @license MIT - Copyright (c) 2020 David Madison
# Permission is hereby granted, free of charge, to any person obtaining a copy
# of this software and associated documentation files (the "Software"), to deal
# in the Software without restriction, including without limitation the rights
# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
# copies of the Software, and to permit persons to whom the Software is
# furnished to do so, subject to the following conditions:
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
# THE SOFTWARE.
import os
import csv
import math
import argparse
def store_filenames(filelist, csv_file):
"""
Takes a list of files and stores their names and a zero-padded sequential
number into a CSV file for later reference.
Parameters:
filelist (list): list of files to store
csv_file (str): path to the CSV file for storing filenames
"""
if os.path.exists(csv_file):
proceed = input("\nWARNING: This CSV file already exists. Continuing will overwrite the file and clear out any saved names. \
YOU WILL NOT BE ABLE RECOVER YOUR FILES IF THE NAMES ARE ALREADY OBSCURED. \n\n Are you sure you want to continue? (y/n)\t")
if proceed != 'y':
quit()
num_files = len(filelist)
num_digits = int(math.log10(num_files)) + 1
with open(csv_file, 'w', newline='') as f:
output = csv.writer(f)
output.writerow(["Original Name", "Rename ID"]) # headers
for index, file in enumerate(filelist):
file_noext = os.path.splitext(file)[0]
new_name = str(index).zfill(num_digits)
output.writerow([file_noext, new_name])
def rename_by_csv(filelist, dir, csv_file, direction, dry_run=True):
"""
From a provided filelist and CSV file, renames files in the given directory
according to the 'Original Name' and 'Rename ID' columns in the file.
Parameters:
filelist (list): list of files to consider for renaming
dir (str): the path to the directory where the files reside
csv_file (str): path to the CSV file that contains the filenames to rename
direction (bool): whether to rename to ID ('True') or rename to original ('False')
dry_run (bool): if 'True', processes filenames without actually renaming anything
"""
if type(direction) is not bool:
print("ERROR: Direction is not a boolean!")
return
with open(csv_file, newline='') as f:
namelist = csv.DictReader(f)
original_key = 'Original Name'
obscure_key = 'Rename ID'
if direction is True: # obscuring
source_key = original_key
dest_key = obscure_key
elif direction is False: # unobscuring
source_key = obscure_key
dest_key = original_key
for row in namelist:
name = row[source_key] + '.' # add period to limit to full name + any extension
rename = row[dest_key]
for file in filelist:
if name in file:
rename = rename + os.path.splitext(file)[1] # add new extension to name
filepath = os.path.join(dir, file)
rename_path = os.path.join(dir, rename)
print("Found file {:s} using name \"{:s}\", renaming to {:s}".format(file, name[:-1], rename))
if dry_run is not True:
try:
os.rename(filepath, rename_path)
except FileNotFoundError as e:
print("ERROR when attempting to rename {:s}".format(filepath))
filelist.remove(file) # remove from the list to prevent rematching this file
break # stop searching for this name
else:
print("WARNING: Could not find matching file for name \"{:s}\" (original: {:s})".format(name[:-1], rename))
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="rename reversal script")
parser.add_argument("directory", help="directory path for the files to rename", type=str)
parser.add_argument("csv", help="file path for the csv file containing renames", type=str)
parser.add_argument("-r", "--reverse", help="reverse direction and apply stored names to files", action='store_true', default=False )
parser.add_argument("-d", "--dryrun", help="do a dry run of the renaming process without renaming any files", action='store_true', default=False )
args = parser.parse_args()
print("\nRename Reverse Script - v1.0")
print("By David Madison, partsnotincluded.com")
print("-----------------------")
print("Directory: {:s}".format(args.directory))
print("CSV File: {:s}".format(args.csv))
print()
files = [f for f in os.listdir(args.directory) if os.path.isfile(os.path.join(args.directory, f))] # get list of files from directory
num_files = len(files)
direction = not args.reverse
if num_files == 0:
print("Error: No files found in {:s}, quitting".format(args.directory))
quit()
if direction == True:
proceed = input("Found {:d} files in {:s}. Continuing will OBSCURE these filenames and save the results to {:s}. Continue? (y/n)\t"\
.format(num_files, args.directory, args.csv))
else:
proceed = input("Found {:d} files in {:s}. Continuing will read from {:s} and revert these files back to their original names. Continue? (y/n)\t"\
.format(num_files, args.directory, args.csv))
if proceed != 'y':
quit()
if direction == True: # not reversing, save names to CSV and obscure
store_filenames(files, args.csv)
rename_by_csv(files, args.directory, args.csv, direction, args.dryrun)
elif direction is False: # reversing, read names from CSV and unobscure
rename_by_csv(files, args.directory, args.csv, direction, args.dryrun)
Step 3: Convert to JPEG
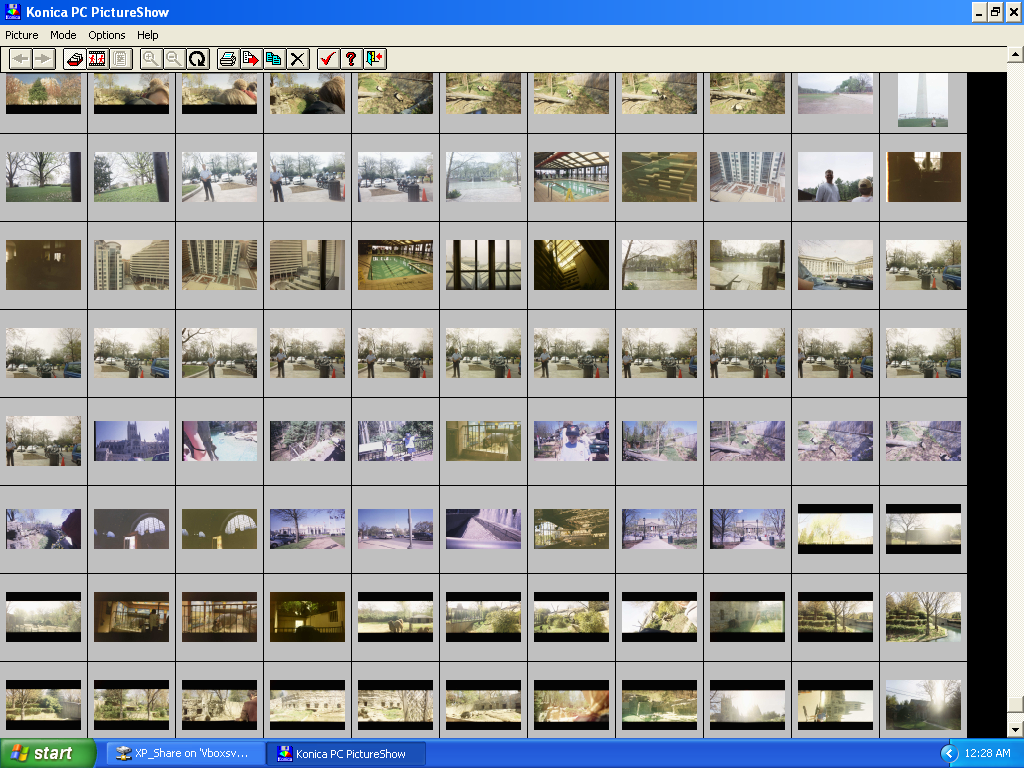
Images loaded and visible in Konica PC PictureShow v3.70 (2001)
So after copying and renaming all of the files (twice…), it’s time to actually convert them from KQP to JPEG. To do this, I’m going to use the original “PC PictureShow” program by Konica. Quoting the original product description circa October 1997:
PC PictureShow™ is a picture viewing utility that displays your pictures all at once in the Picture Index, or in an automatic PC PictureShow™ one after another. Pictures can have comments or notes added to each picture or be rotated for viewing in the correct orientation. PC PictureShow™ also allows you to convert and export the pictures into standard bitmap (BMP) or pict (PIC) image formats for use in other programs such as word processors, paintbrush, or image enhancement software, or into JFIF image format for transmission over online services such as the Internet. You can advance through the pictures forwards and backwards, add text notes, and copy pictures to the clipboard. Pictures can also be removed from PC PictureShow™ or zoomed to fill the screen.
Emphasis mine. JFIF is an acronym for the “JPEG File Interchange Format” and “defines supplementary specifications for the container format that contains the image data encoded with the JPEG algorithm”. Although JFIF has since been replaced by Exif, the underlying image data in a JFIF file is JPEG – a format widely used and supported by virtually all modern image software.
Note: JPEG compression is lossy, and although in an ideal world I would convert to a “lossless” format for archival purposes, the KQP files on the floppy drives are already compressed which defeats the purpose. What can you do.
Virtual Time Machine

The Windows XP image booting in VirtualBox
Since the Konica software doesn’t run on Windows 10, our best option is to install an older version of Windows – either on a computer of that vintage, or in this case on a modern computer using “virtualization” technology.
I followed this handy guide to download the “Windows XP Mode” files from Microsoft and create a virtual machine running Windows XP for free with Oracle VirtualBox. Although Windows XP is just outside of our supported software window having launched in the fall of 2001, it’s still old enough to support the Konica program without issue.
After setting up XP and installing the VirtualBox “guest additions”, I created a network share to transfer files from the host PC to the virtual computer. Then I copied over the .KQP image files I took from the floppies and got ready for the image conversion.
Conversion
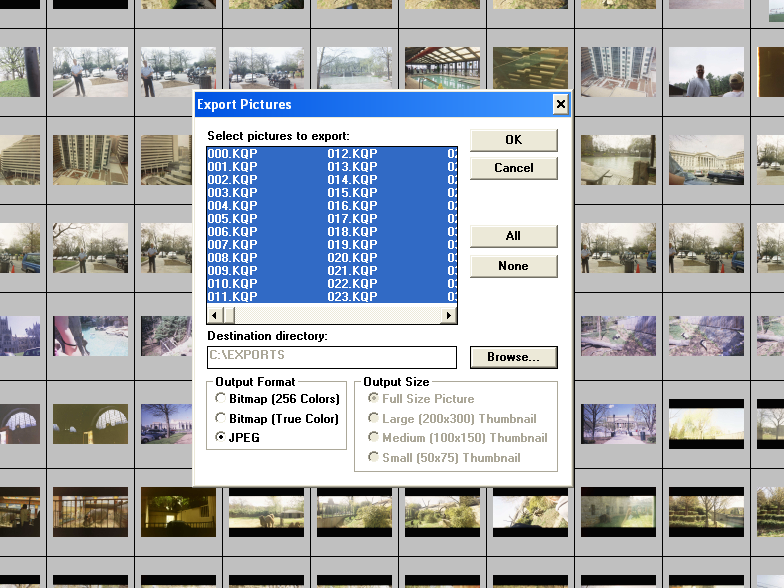 To do the conversion itself I needed a copy of PC PictureShow. Luckily for me the software executable and dependencies are included on each floppy disk, so I copied the most recent version (3.70 circa April 2001) and ran the
To do the conversion itself I needed a copy of PC PictureShow. Luckily for me the software executable and dependencies are included on each floppy disk, so I copied the most recent version (3.70 circa April 2001) and ran the PCPS.EXE file to start the program.
If you’re not so lucky as to have a handful of old Konica floppy disks on hand, I was able to find a version of PC PictureShow available online via the Internet Archive (v3.06, download here).
As soon as the software loads it prompts you to “Select [a] Directory” where “Konica Quality Photo or JPEG file[s]” reside. After navigating to the folder with all of my .KQP files that I copied from the floppy disks, the program instantly refreshed and I saw all of my photo thumbnails in their old, musty, poorly-scanned glory. It looks as though these images have successfully survived their twenty-year cold storage in a shoebox!
From here exporting to JPEG could not be any simpler. From the top menu, go to Picture -> Export and the export options dialog box will pop up. Choose an output directory, set “JPEG” as the output format, click the “All” button to select all images, then hit the “OK” button to export.
Step 4: Renaming Back
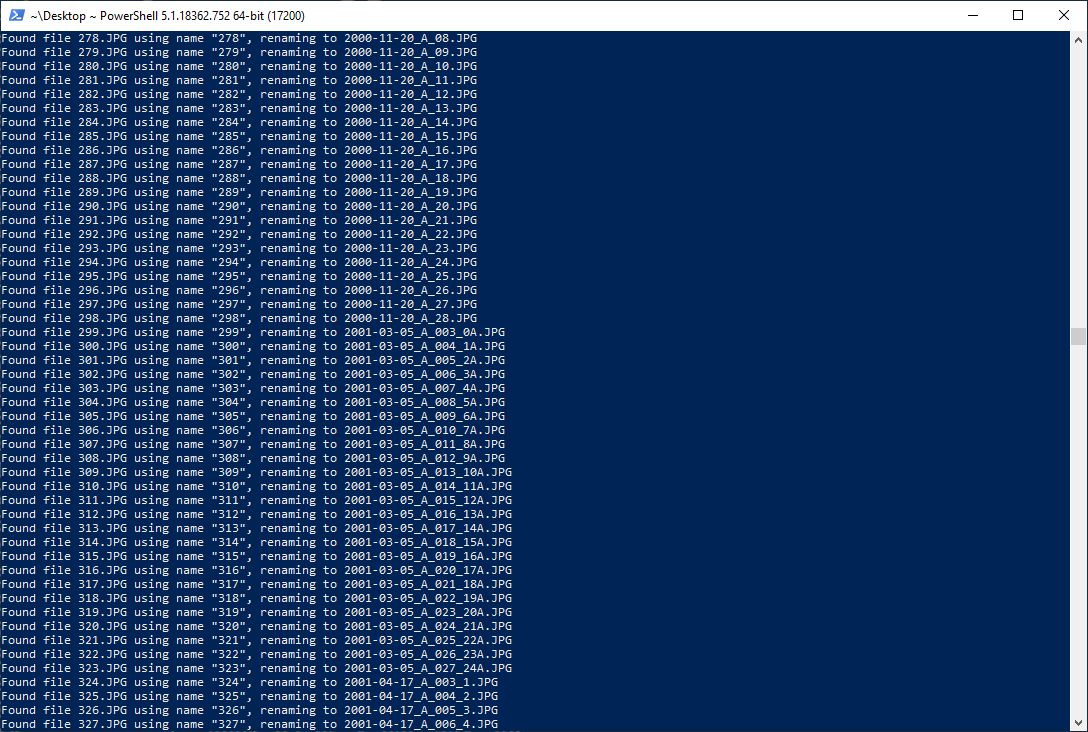
Python script renaming the JPEG files to their original names
After closing out of PC PictureShow and copying the exported JPEGs back into Windows 10, the final step is to take the converted JPEG files and rename them back to their original filenames using the same script I developed in Step 2:
python .\Rename_Reverse.py "C:/Users/Dave/Desktop/Exports" "C:/Users/Dave/Desktop/floppyphotos.csv" -r
Then after giving the script a second or two to process, all of the sequentially named JPEGs are returned to their original filenames.
And with that, we’re done! Using a handful of Python scripts and a virtual machine, I’ve turned a dusty old stack of floppy disks containing photos in an obsolete format into a collection of well-organized JPEGs that will last for years to come.
Proprietary file formats are always a pain, and this task was originally quite daunting until I realized I could just use the original software through a virtual machine. Still, it was definitely an adventure to get everything working smoothly.
Do you have your own collection of dusty .KQP files? Share a comment below with your own file conversion story!



4 Comments
SAS · October 15, 2020 at 11:29 am
Thank you for posting this. I just found some old floppies from Konica when I was in college, graduating in 1997. The oldest computer I have, unfortunately, is from my graduate days, 2002 – 2006, and it is so slow, so I don’t think I’ll be able to run this Konica picture conversion program you mentioned due to the Windows XP issue. But I do have the prints of all these albums, so may just opt to use a service that scans them.
SAS · October 15, 2020 at 11:34 am
Actually, looking on the web, I found a link to pcps5.exe that installed on my Windows 10 computer. So I can convert them.
JerryB · December 19, 2021 at 3:53 pm
Thank you for this information. Unfortunately after creating the virtual machine, sharing my drive with Konica pictures, and downloading Konica software; Could not get it to run on the VM. It errored with the message “Can’t run 16-bit Windows Program – Can not run the file z:\mypath\pcps306.exe (or one of its components). Check to insure that the path and filename are correct and that all the required libraries are available.”
Also got this message with the zip version of the file download.
Any suggestions as to what else may be missing?
Dave · December 20, 2021 at 6:40 am
Hi Jerry. I believe that’s an error with the 8.3 file name compatibility, which means there’s something in the path that it doesn’t like. Try moving the executable to the root of the C:\ drive.